@article{suranigailmard2025,
title={What Is the Law? A System for Statutory Research (STARA) with Large Language Models},
author={Surani, Faiz and Gailmard, Lindsey A and Casasola, Allison and Magesh, Varun and Robitschek, Emily J and Ho, Daniel E},
journal={Proceedings of the 20th International Conference on Artificial Intelligence and Law},
year={2025}
url={https://dho.stanford.edu/wp-content/uploads/STARA.pdf}
}System Design and Results
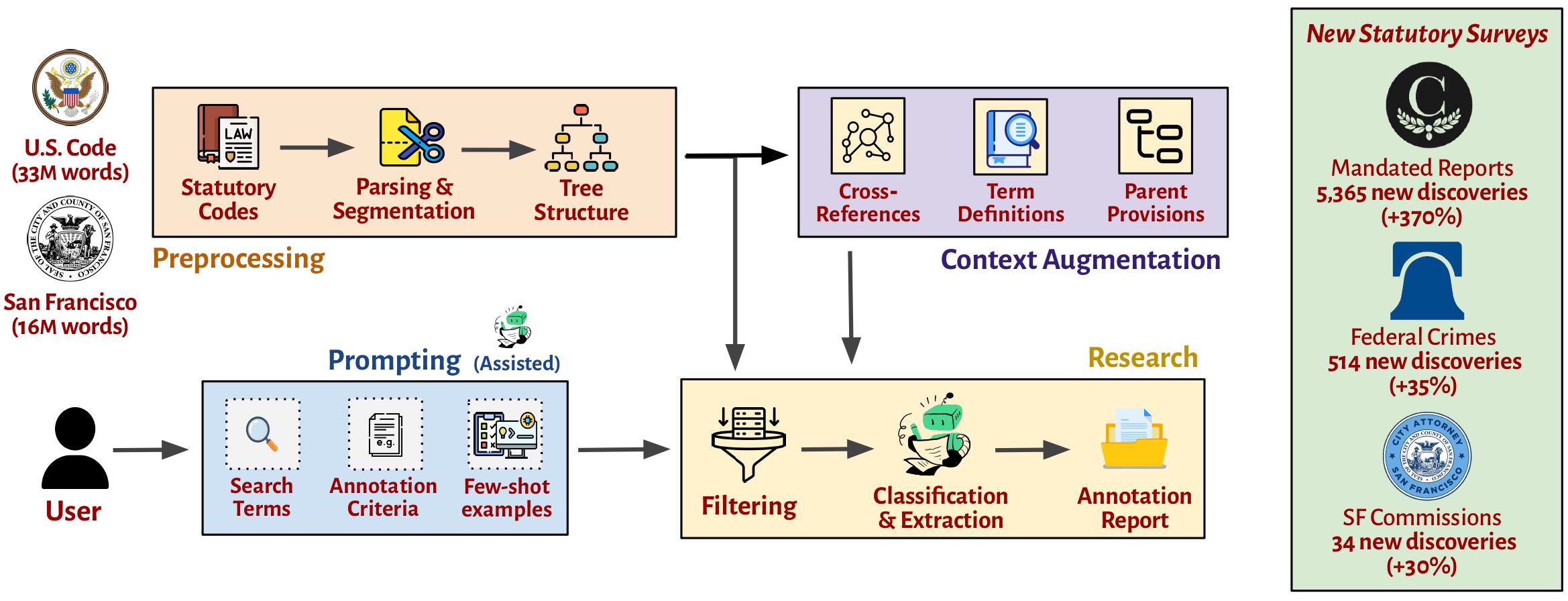
Figure: Left: Illustration of the STARA system’s components. Right: STARA’s contribution to statutory research, showing the number of newly-documented provisions (and percentage improvement over previous datasets) across three validation tasks: congressionally-mandated reports and criminal statutes in the United States Code, and commissions established by the San Francisco Municipal Code.
| System | # Found | Precision | Recall |
|---|---|---|---|
| STARA | 1,983 | 0.98 | 0.998 |
| Gemini Deep Research | 282 | 0.890 | 0.144 |
| OpenAI Deep Research | 84 | 0.881 | 0.044 |
| Westlaw AI Jurisdictional Survey | 113 | 0.415 | 0.072 |
Table: Comparison of STARA with other AI research systems on federal criminal statutes task. STARA locates 7 times as many provisions as the best-performing comparison system.
| Configuration | Precision | Recall | Extraction |
|---|---|---|---|
| LLM Baseline | 0.58 | 0.990 | 0.28 |
| +Prompt Engineering | 0.76 | 0.987 | 0.32 |
| +Basic Context | 0.96 | 0.984 | 0.70 |
| STARA | 0.96 | 0.998 | 0.76 |
Table: Ablation study results on federal criminal statutes task, demonstrating the importance of different components of STARA’s architecture. Extraction measures accuracy and completeness in identifying offense descriptions and penalties.